-

As artificial intelligence reshapes how we interact with data, one architectural shift stands out: the move from CPU-centric computing to GPU-dominant infrastructure. But why did this happen? And what makes GPUs so uniquely suited for AI workloads? Let’s unpack the evolution, the math, and the mechanics behind this transformation.
-
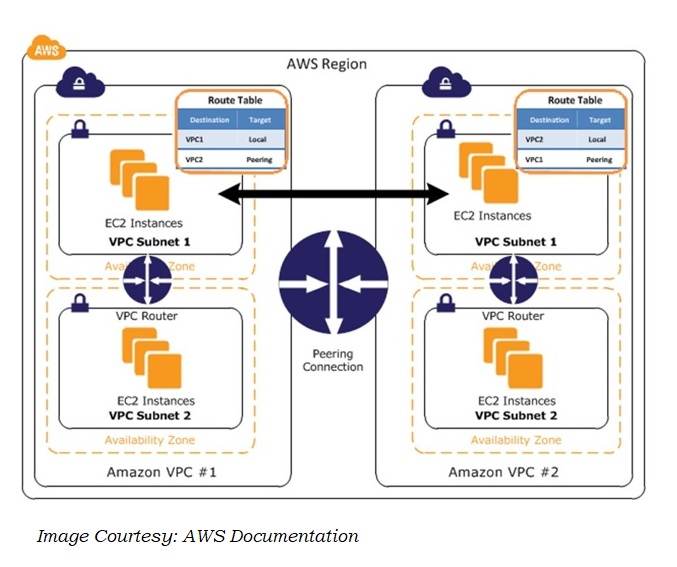
How to share resource present in two separate VPCs? It is VPC Peering. Connecting two cloud environments make it possible to use each other’s resources.
-

Resources in a cloud environment are at different level of scope. While cloud providers operates from multiple geographic regions, many resources are accessible globally, but some are at much smaller scope (called AZ).
-
Glacier is a low cost Cold-Data-Storage service used for data archival. It exposes a REST interface. “Archive” and “Vault” are the two main components in Glacier service.
-
Glad to add another credential …… The AWS certified solutions architect badge!
-

Network Address Translation in AWS world is done via a dedicated EC2 instance as well as an Amazon provisioned managed component. So which one should the users use?
-
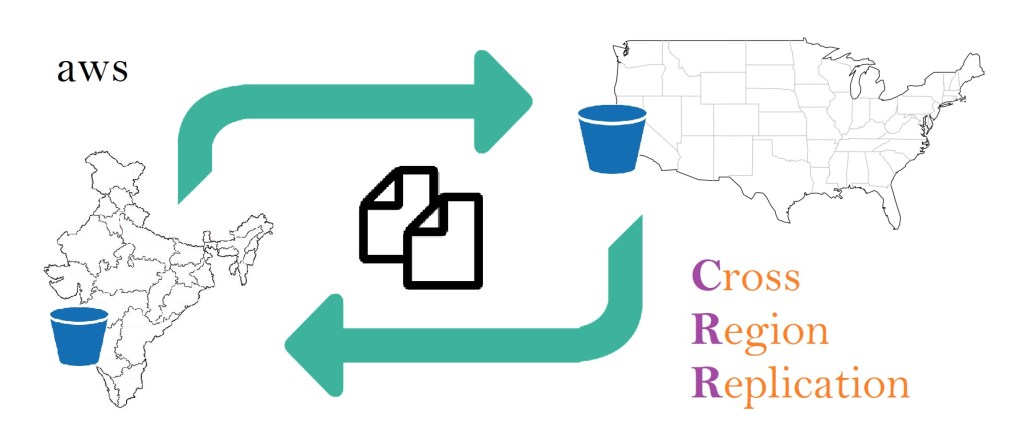
Cross Region Replication (CRR) is a feature of S3 that can be activated at Bucket level by adding a replication configuration to the source bucket. A bucket’s automatic replication is specific to a Region and it is not Global. With CRR, automatic data replication can be setup across regions.
-

The Simple Storage Service is a secure, durable, highly scalable and highly available Object Storage by AWS. Object Store means we can store Files but cannot install software. S3 provides easy to use, web service interface to store/retrieve any amount of data from anywhere.
-

S3 Security is divided in four categories- Privacy, Log Trail, Access Permissions and Encryption.
-

Access Control Lists plays an instrumental role in network security. In AWS world, Network ACLs (NACLs) are referred as “Security at the Gate”, since rules are applied at Subnet level
-

A Security Group (SG) is a firewall that controls traffic at the NIC level of the Virtual Server (An EC2 instance running virtually over a physical hardware)
-
Trying to login to an EC2 instance over Internet? Not able to connect? Use this checklist to verify, that each piece of configuration is in place.
-

When an organization starts working with AWS, they create a private cloud. A private cloud that contains IT resources for use by the organization on which it has full control. This post outlines some basic facts about AWS private cloud.
-

IAM allow Admins to manage users and their level of access to AWS resources. IAM gives centralized access to manage permissions. IAM can act on Users and Groups, can create or use Policy documents and define Roles.
-
In an elastic cluster, there are many entities that makes up a functioning cluster. Nodes, Primary Shards and Replicas are the ones frequently getting referred in documentation and articles.
-
Another Certification Bagged … 🙂 MapR’s Certification exams are very conceptual and test knowledge deeply. This certification exam covers a balance of Conceptual and API level questions. This is not at all a low hanging fruit. I used the book HBase Definitive Guide extensively to study the Architecture and internals of HBase. Certain YouTube video…
-
Happy to share the earning of MCSD certification 🙂 Verification URL: https://verify.skilljar.com/c/5if4ohmy68dr Certifications solidify the conceptual knowledge. Spark carries a lot of concepts as well. The Learning Spark Book as well as certain YouTube Videos are a must to build conceptual knowledge. YouTube videos by Sameer Farooque and Brian Clapper are sources. These Certification exams…
-

Log file analysis is popular usecase in Big Data world. Log files contains evidence of historical events that an application witnessed under their execution environment. Monitoring applications intend to find out traces of actual events that happened during program execution. Several analysis usecases are possible from simply counting occurrence of some event to specific processing.
-
. Analysis and Analyzers Elastic Search breaks (tokenizes) data in the document and build index of words (tokens). For each token, it points to the documents that matches the token. The words (tokens) are transformed a particular manner before being stored in the index. This process of breaking the document in a set of words…
-
. EMP and DEPT tables are pretty popular between Oracle users. These tables were very handy in quickly trying new queries. Also, there exists a DUAL table in Oracle that was pretty useful in evaluate expressions, like- “Select (SYSDATE + 1/24) as OneHourFromNow FROM DUAL“. These tables doesn’t exists in Hive, but we can create…
-

. Happy to share the earning of CCDH certification 🙂 Verification URL: http://certification.cloudera.com/verify (with License # 100-013-285) . Loads of conceptual as well as programming questions that include multiple choice questions as well. Reading Hadoop: The Definitive Guide and Programming Hive a couple of times and practicing Map-Reduce programming model rigorously, was instrumental in clearing the exams. Setting up…
-

. There are few type of UDFs that we can write in Hive. Functions that act on each column value passed to it, e.g. Select Length(name) From Customer Specific functions written for a specific data type (simple UDFs) Generic functions written to working with more than one data type Functions that act on a group…
-

. HCatalog is an extension of Hive and in a nutshell, it exposes the schema information in Hive Metastore such that applications outside of Hive can use it. The objective of HCatalog is to hold the following type of information about the data in HDFS – Location of the data Metadata about the data (e.g.…
-
. There are a few type of UDFs that we can write in Hive. Functions that act on each column value passed to it, e.g. Select Length(name) From Customer Specific functions written for a specific data type Generic functions written to working with more than one data type (GenericUDF) Functions that act on a group…
-

. emp = LOAD ‘/path/to/data/file/on/hdfc/Employees.txt’ [ USING PigStorage(‘ ‘) ] AS ( emp_id: INT, name: CHARARRAY, joining_date: DATETIME, department: INT, salary: FLOAT, mgr_id: INT, residence: BAG { b:(addr1: CHARARRAY, addr2: CHARARRAY, city: CHARARRAY) }) ; The Alias for data in file “Employees.txt” is emp and using emp,…
-
. UDFs (User Defined Functions) are ways in pig to extend its functionality. There are two type of UDFs that we can write in pig – Evaluate (extends from EvalFunc base class) Load/Store functions (extends from LoadFunc base class) Here we will stepwise develop an Evaluate UDF. Lets start by conceptualizing a UDF (named VowelCount)…
-
. — emp = LOAD ‘Employees.txt’ … Data in text file resembles the “EMP” table in Oracle — dept = LOAD ‘Dept.txt’ …….. Data in text file resembles the “DEPT” table in Oracle — Filter data in emp to only those whose job is Clerk. Filtered_Emp = FILTER emp BY (job == ‘CLERK’); — Supports…
-
. Simple: INT and FLOAT are 32 bit signed numeric datatypes backed by java.lang.Integer and java.lang.Float Simple: LONG and DOUBLE are 64 bit signed numeric Java datatypes Simple: CHARARRAY (Unicode backed by java.lang.String) Simple: BYTEARRAY (Bytes / Blob, backed by Pig’s DataByteArray class that wraps byte[]) Simple: BOOLEAN (“true” or “false” case sensitive) Simple: DATETIME…
-
. Pig Statements — Load command loads the data — Every placeholder like “A_Rel” and “Filter_A” are called Alias, and they are useful — in holding the relation returned by pig statements. Aliases are relations (not variables). A_Rel = LOAD ‘/hdfs/path/to/file’ [AS (col_1[: type], col_2[: type], col_3[: type], …)] ; — Record set returned by…
-
Pig is a data flow language developed at Yahoo and is a high level language. Pig programs are translated into a lower level instructions supported by underlying execution engine. Pig is designed for working on complex operations with speed.
-
MapReduce default settings
-
. Sqoop is a utility that can be used to transfer data between SQL based relational data stores tO/from hadoOP. The main operation this utility carry out is performing a data Import to Hadoop from supported relational data sources and Exporting data back to them. Sqoop uses connectors as extensions to connect to data stores.…
-
. Apache Hive is an abstraction on top of HDFS data, that allow querying the data using the familiar SQL like language, called HiveQL (Hive Query Language). Hive was developed at Facebook to allow data analysts to query data using an SQL like language. Hive has limited commands and is similar to basic SQL (advance SQL options…
-
Architecture is a branch of design. So every architectural work is a kind of design, but the reverse is not true.
-
Casually speaking, Software architecture is the careful partitioning or subdivision of a system as whole, into sub-parts with specific relationship between these sub-parts. This partitioning is what allows different people (or group(s) of people) to work together cooperatively to solve a much bigger problem, then any of them could solve by individually dealing with…
-
This article explains how to create an Email and make it appear to the user that a Self-Created Message is Received from a Different Sender.
-
Status Returned By BlackBerry API During "Data Connection Refused" Conditions
-
Installing an ISAPI Extension as a Wildcard Handler
-
Greetings !! Wikipedia is great source of free knowledge for nearly all of us. Lets start with supporting Wikipedia : There is also a great source of software engineering audio podcasts available, that you can find at: http://www.se-radio.net. If you like the podcast, you may want to support SE-Radio too: Will meet you soon here,…
-
Subscribe
Subscribed
Already have a WordPress.com account? Log in now.
