Technical
-

Network Address Translation in AWS world is done via a dedicated EC2 instance as well as an Amazon provisioned managed component. So which one should the users use?
-
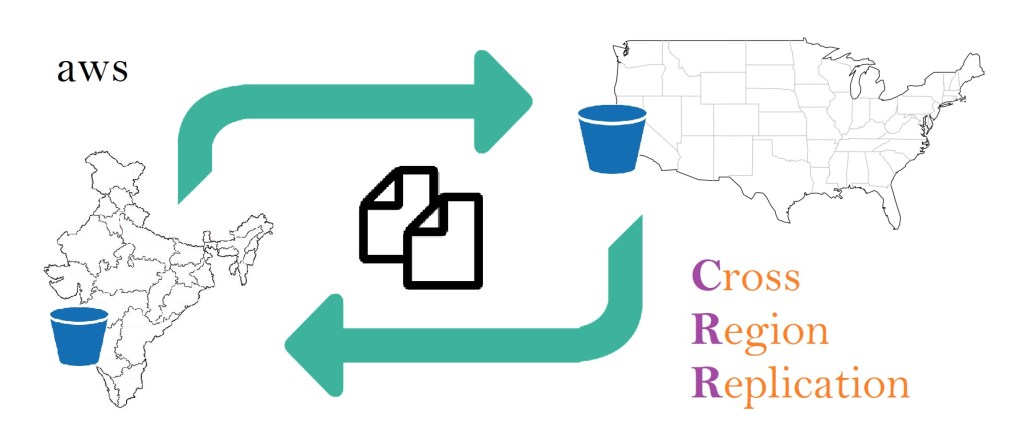
Cross Region Replication (CRR) is a feature of S3 that can be activated at Bucket level by adding a replication configuration to the source bucket. A bucket’s automatic replication is specific to a Region and it is not Global. With CRR, automatic data replication can be setup across regions.
-

Access Control Lists plays an instrumental role in network security. In AWS world, Network ACLs (NACLs) are referred as “Security at the Gate”, since rules are applied at Subnet level
-

A Security Group (SG) is a firewall that controls traffic at the NIC level of the Virtual Server (An EC2 instance running virtually over a physical hardware)
-
Trying to login to an EC2 instance over Internet? Not able to connect? Use this checklist to verify, that each piece of configuration is in place.
-

When an organization starts working with AWS, they create a private cloud. A private cloud that contains IT resources for use by the organization on which it has full control. This post outlines some basic facts about AWS private cloud.
-

IAM allow Admins to manage users and their level of access to AWS resources. IAM gives centralized access to manage permissions. IAM can act on Users and Groups, can create or use Policy documents and define Roles.
-
Happy to share the earning of MCSD certification 🙂 Verification URL: https://verify.skilljar.com/c/5if4ohmy68dr Certifications solidify the conceptual knowledge. Spark carries a lot of concepts as well. The Learning Spark Book as well as certain YouTube Videos are a must to build conceptual knowledge. YouTube videos by Sameer Farooque and Brian Clapper are sources. These Certification exams
-
. Analysis and Analyzers Elastic Search breaks (tokenizes) data in the document and build index of words (tokens). For each token, it points to the documents that matches the token. The words (tokens) are transformed a particular manner before being stored in the index. This process of breaking the document in a set of words
-
. EMP and DEPT tables are pretty popular between Oracle users. These tables were very handy in quickly trying new queries. Also, there exists a DUAL table in Oracle that was pretty useful in evaluate expressions, like- “Select (SYSDATE + 1/24) as OneHourFromNow FROM DUAL“. These tables doesn’t exists in Hive, but we can create
-

. Happy to share the earning of CCDH certification 🙂 Verification URL: http://certification.cloudera.com/verify (with License # 100-013-285) . Loads of conceptual as well as programming questions that include multiple choice questions as well. Reading Hadoop: The Definitive Guide and Programming Hive a couple of times and practicing Map-Reduce programming model rigorously, was instrumental in clearing the exams. Setting up
-

. There are few type of UDFs that we can write in Hive. Functions that act on each column value passed to it, e.g. Select Length(name) From Customer Specific functions written for a specific data type (simple UDFs) Generic functions written to working with more than one data type Functions that act on a group
-

. HCatalog is an extension of Hive and in a nutshell, it exposes the schema information in Hive Metastore such that applications outside of Hive can use it. The objective of HCatalog is to hold the following type of information about the data in HDFS – Location of the data Metadata about the data (e.g.
-
. There are a few type of UDFs that we can write in Hive. Functions that act on each column value passed to it, e.g. Select Length(name) From Customer Specific functions written for a specific data type Generic functions written to working with more than one data type (GenericUDF) Functions that act on a group
-
. Simple: INT and FLOAT are 32 bit signed numeric datatypes backed by java.lang.Integer and java.lang.Float Simple: LONG and DOUBLE are 64 bit signed numeric Java datatypes Simple: CHARARRAY (Unicode backed by java.lang.String) Simple: BYTEARRAY (Bytes / Blob, backed by Pig’s DataByteArray class that wraps byte[]) Simple: BOOLEAN (“true” or “false” case sensitive) Simple: DATETIME
